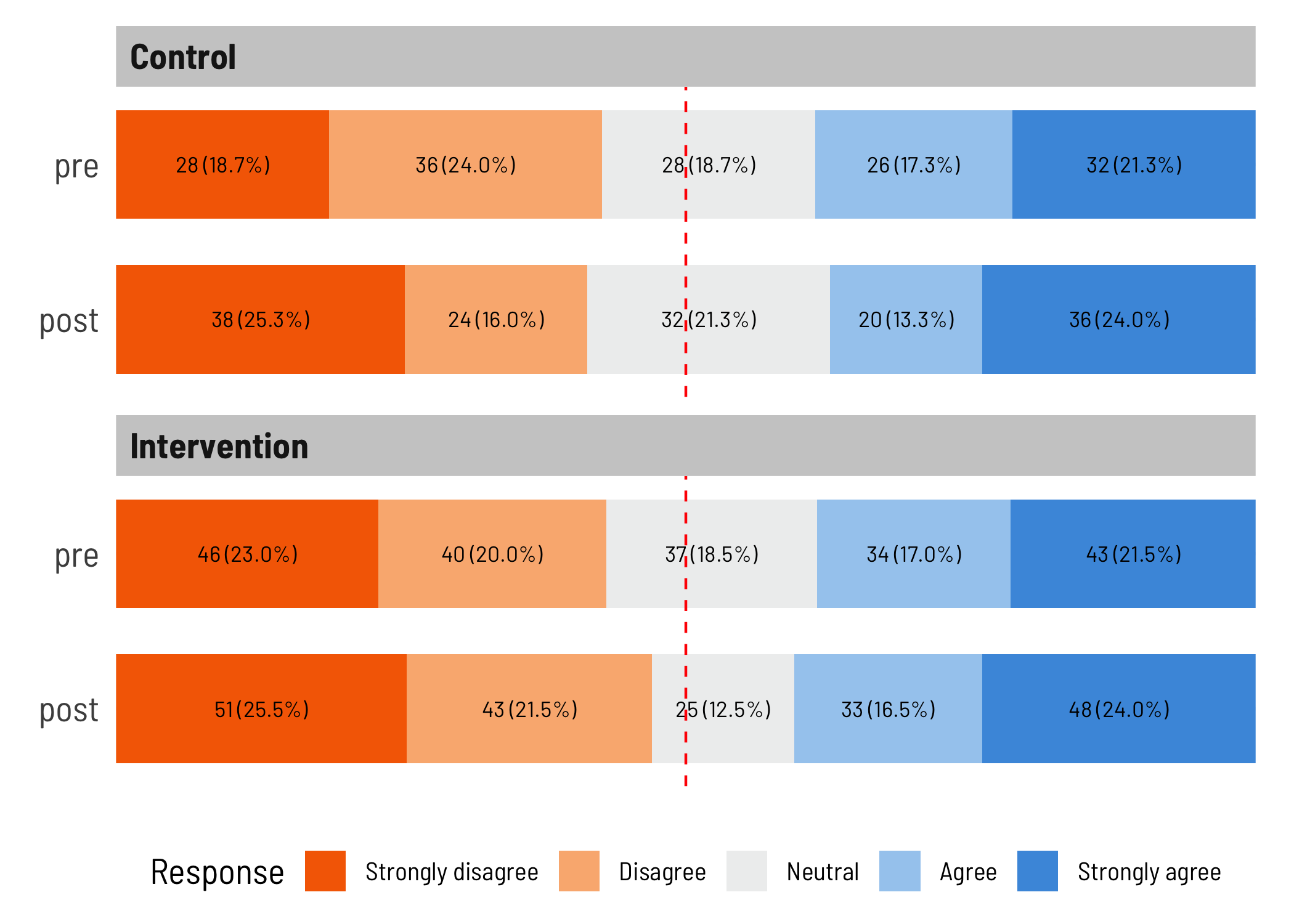
bidirect_plot <- function(data,
grouping_var,
facet_var,
outcome_var,
base_size = 14,
legend_size = base_size - 4,
axis_y_size = base_size,
label_size = 3,
label_threshold = 5,
label_round = 1,
fill_colour = c("#f56b00", "#fab580", "#eeefef","#a5ccef", "#4a99de"),
axis_y_label_lineheight = 0.6,
legend.position = "bottom",
legend.title.position = "left",
hline = TRUE,
hline_threshold = 50,
...){
# Reverse the `grouping_var` factors for consistent colouring
data <- data %>%
mutate(!!sym(grouping_var) := fct_rev(!!sym(grouping_var)))
# Calculate the counts and proportions for each group
plot_dat <- data %>%
count(!!sym(outcome_var),
!!sym(facet_var),
!!sym(grouping_var)) %>%
group_by(!!sym(facet_var),
!!sym(grouping_var)) %>%
mutate(prop = 100*n/sum(n),
pos = cumsum(prop) - 0.5*prop) %>%
ungroup %>%
mutate(!!sym(outcome_var) := fct_rev(!!sym(outcome_var)))
# Create the plot!
suppressMessages({
plot <- plot_dat %>%
ggplot(aes(x = !!sym(grouping_var),
y = prop,
fill = !!sym(outcome_var))) +
geom_bar(stat = "identity",
position = "stack",
width = 0.7) +
geom_text(aes(label = ifelse(prop >= label_threshold,
paste0(n, " (", round_vec(prop, label_round), "%)"), ""),
y = pos),
size = label_size,
family = "Barlow") +
facet_wrap(as.formula(paste("~", facet_var)),
ncol = 1) +
coord_flip() +
thekidsbiostats::theme_institute(base_size = base_size,
...) +
scale_fill_manual(values = rev(fill_colour)) +
scale_y_continuous(expand = c(0, 0)) + # y axis in-line with plot labels (no spacing)
scale_x_discrete(expand = expansion(add = c(0.5, 0.5))) + # Spacing between bar and plot area (bottom, top)
guides(fill = guide_legend(title = "Response",
reverse = TRUE)) +
theme(# x axis formatting
axis.title.x = element_blank(),
axis.ticks.x = element_blank(),
axis.text.x = element_blank(),
# y axis formatting
axis.title.y = element_blank(),
axis.text.y = element_text(size = axis_y_size,
lineheight = axis_y_label_lineheight),
# Legend formatting
legend.position = legend.position,
legend.title.position = legend.title.position,
legend.text = element_text(size = legend_size),
# Miscellaneous formatting
panel.grid.major.x = element_blank(),
plot.margin = margin(t = 10, r = 15, b = 5, l = 15))
})
if (hline == TRUE){
plot <- plot +
geom_hline(yintercept = hline_threshold,
linetype = "dashed",
colour = "red")
} else if (hline == FALSE){
plot <- plot
}
return(plot)
}